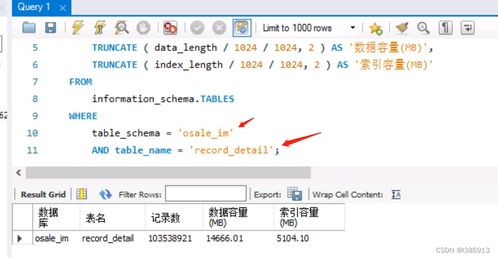
实时数仓-继续更新
镜像服务器整理
关于整个机器
rm -rf /tmp/*
rm -rf /usr/tmp/*
rm -rf /var/log/*
rm -rf /var/run/log/*
rm -rf /root/*
rm -rf /paimon
关于Dinky
rm -rf /opt/service/dinky-release-1.17-1.0.3/logs/*
rm -rf /opt/service/dinky-release-1.17-1.0.3/tmp/*
关于Hadoop
rm -rf /opt/service/hadoop-3.2.4/data/*
rm -rf /opt/service/hadoop-3.2.4/logs/*
rm -rf /opt/service/hadoop-3.2.4/tmp/*
关于Kafka
rm -rf /opt/service/kafka_2.12-3.0.0/data/*
rm -rf /opt/service/kafka_2.12-3.0.0/logs/*
关于zookeeper
rm -rf /opt/service/zookeeper-3.5.10/data/zkdata/*
rm -rf /opt/service/zookeeper-3.5.10/data/zkdatalog/*
rm -rf /opt/service/zookeeper-3.5.10/logs/*
JDK(根底组件)
https://www.oracle.com/java/technologies/downloads/archive/
解压后装备`/etc/profile`
#JAVA
export JAVA_HOME=/opt/service/jdk1.8.0_401
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
使指令收效
source /etc/profile
查验Java版别
java -version
MYSQL
装置脚本
#!/bin/bash
set -x
function Install_Mysql(){
while :
do
read -p "Do you need to install MySQL(yes/no): " my_result
if [ "$my_result" == "no" ];then
which mysql >/dev/null 2>&1
if [ "$?" != "0" ];then
echo "MySQL client is not installed on this machine. Start to install now"
cd $dir
wget -O "mysql5.7.tar.gz" https://s3-gzpu.didistatic.com/pub/mysql5.7.tar.gz
mkdir -p $dir/mysql/ && cd $dir/mysql/
tar -zxf $dir/mysql5.7.tar.gz -C $dir/mysql/
rpm -ivh $dir/mysql/mysql-community-common-5.7.36-1.el7.x86_64.rpm
rpm -ivh $dir/mysql/mysql-community-libs-5.7.36-1.el7.x86_64.rpm
rpm -ivh $dir/mysql/mysql-community-client-5.7.36-1.el7.x86_64.rpm
fi
read -p "Please enter the MySQL service address: " mysql_ip
read -p "Please enter MySQL service port(default is 3306): " mysql_port
read -p "Please enter the root password of MySQL service: " mysql_pass
if [ "$mysql_port" == "" ];then
mysql_port=3306
fi
break
elif [ "$my_result" == "yes" ];then
read -p "Installing MySQL service will uninstall the installed(if any), Do you want to continue(yes/no): " option
if [ "$option" == "yes" ];then
cd $dir
wget -O "mysql5.7.tar.gz" https://s3-gzpu.didistatic.com/pub/mysql5.7.tar.gz
rpm -qa | grep -w -E "mariadb|mysql" | xargs yum -y remove >/dev/null 2>&1
mv -f /var/lib/mysql/ /var/lib/mysqlbak$(date "+%s") >/dev/null 2>&1
mkdir -p $dir/mysql/ && cd $dir/mysql/
tar -zxf $dir/mysql5.7.tar.gz -C $dir/mysql/
yum -y localinstall mysql* libaio*
systemctl start mysqld
systemctl enable mysqld >/dev/null 2>&1
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
mysql -NBe "alter user USER() identified by '$mysql_pass';" --connect-expired-password -uroot -p$old_pass
if [ $? -eq 0 ];then
mysql_ip="127.0.0.1"
mysql_port="3306"
echo "Mysql database installation completed"
echo -------- Mysql Password $old_pass ---------
else
echo -e "${RED} Mysql database configuration failed. The script exits ${RES}"
exit
fi
break
else
exit 1
fi
else
Printlog "Input error, please re-enter(yes/no)"
continue
fi
done
}
#参数声明
dir=`pwd`
RED='\E[1;31m'
RES='\E[0m'
#调用
Install_Mysql
SSH(集群免密)
--参阅地址
https://www.jianshu.com/p/b71c58a598b5
端口:22
修正装备文件(三台) `/etc/hosts`
echo "::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.99.215 bigdata01 iZ2ze3nalp8guto80cb08tZ
192.168.99.216 bigdata02 iZ2ze3nalp8guto80cb08sZ
192.168.99.214 bigdata03 iZ2ze3nalp8guto80cb08rZ" > /etc/hosts
相互免密设置(三台)
ssh-keygen -t rsa
.ae[%oTuPP~G%}3,hy{UPB&&}8M}18
#接连三次回车
ssh-copy-id root@bigdata01
#输入暗码
#Odds!@#123
ssh-copy-id root@bigdata02
#输入暗码
ssh-copy-id root@bigdata03
#输入暗码
Zookeeper(集群)
分布式和谐服务,能够协助分布式应用程序****完成数据同步
-- 参阅地址
https://www.cnblogs.com/maoxianwan/articles/17486380.html
端口:2181/2888/3888
解压后装备`/etc/profile`
#ZOOKEEPER
export ZOOKEEPER_HOME=/opt/hadoop/apache-zookeeper-3.8.0-bin/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
使指令收效
source /etc/profile
修正装备文件` ```$ZOOKEEPER_HOME/conf/zoo.cfg``` `
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/service/zookeeper-3.5.10/data/zkdata
dataLogDir=/opt/service/zookeeper-3.5.10/data/zkdatalog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
在目录dataDir创立服务节点编号文件myid,与server.后的数字对应
自定义集群启停脚本
#!/bin/bash
for host in bigdata01 bigdata02 bigdata03
do
case $1 in
"start"){
echo " "
echo "--------------- 启 动 zookeeper ---------------"
echo "------------ $host zookeeper -----------"
ssh $host "source /etc/profile; zkServer.sh start"
};;
"stop"){
echo " "
echo "--------------- 关 闭 zookeeper ---------------"
echo "------------ $host zookeeper -----------"
ssh $host "source /etc/profile; zkServer.sh stop"
};;
"status"){
echo " "
echo "-------------- 检查zookeeper状况 --------------"
echo "------------ $host zookeeper -----------"
ssh $host "source /etc/profile; zkServer.sh status"
};;
esac
done
`chmod +x /bash/zkCluster.sh`
`cp /bash/zkCluster.sh /bin/`
测验
`zkCluster.sh status`
Kafka(集群)
--参阅地址
https://blog.csdn.net/snipercai/article/details/131812772
端口:9092/9999
解压后装备`/etc/profile`
#HADOOP
export HADOOP_HOME=/opt/service/hadoop-3.2.4
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Hadoop(集群)
--参阅地址
https://blog.csdn.net/snipercai/article/details/131812772
端口:9000/9870/8485/10020/19888/8088
解压后装备`/etc/profile`
#HADOOP
export HADOOP_HOME=/opt/service/hadoop-3.2.4
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
各装备文件
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 设置默许运用的文件体系 Hadoop支撑file、HDFS、GFS等文件体系 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ccns</value>
</property>
<!-- 设置Hadoop暂时目录途径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/service/hadoop-3.2.4/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
<!-- 设置Hadoop本地保存数据途径 -->
<property>
<name>hadoop.data.dir</name>
<value>/opt/service/hadoop-3.2.4/data</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 文件体系垃圾桶保存时刻 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--履行hdfs的nameservice为ns,留意要和core-site.xml中的称号保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ccns</value>
</property>
<!-- nameservice包括的namenode,ns集群下有两个namenode,分别为nn1, nn2 -->
<property>
<name>dfs.ha.namenodes.ccns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的rpc地址和端口号,rpc用来和datanode通讯,默许值:9000-->
<property>
<name>dfs.namenode.rpc-address.ccns.nn1</name>
<value>bigdata01:9000</value>
</property>
<!-- nn2的rpc地址和端口号,rpc用来和datanode通讯,默许值:9000-->
<property>
<name>dfs.namenode.rpc-address.ccns.nn2</name>
<value>bigdata02:9000</value>
</property>
<!-- nn1的http地址和端口号,web客户端 -->
<property>
<name>dfs.namenode.http-address.ccns.nn1</name>
<value>bigdata01:9870</value>
</property>
<!-- nn2的http地址和端口号,web客户端 -->
<property>
<name>dfs.namenode.http-address.ccns.nn2</name>
<value>bigdata02:9870</value>
</property>
<!-- 指定namenode的元数据在JournalNode上寄存的方位,namenode2能够从journalnode集群里的指定方位上获取信息,到达热备作用 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata01:8485;bigdata02:8485;bigdata03:8485/ccns</value>
</property>
<!-- 装备失利主动切换完成办法,客户端衔接可用状况的NameNode所用的署理类,默许值:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider -->
<property>
<name>dfs.client.failover.proxy.provider.ccns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 装备阻隔机制,HDFS的HA功用的防脑裂办法。主张运用sshfence(hadoop:9922),括号内的是用户名和端口,留意,2台NN之间可免暗码登陆.sshfences是避免脑裂的办法,确保NN中仅一个是Active的,假如2者都是Active的,新的会把旧的强制Kill -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 敞开NameNode失利主动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定上述选项ssh通讯运用的密钥文件在体系中的方位 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 指定JournalNode在本地磁盘寄存数据的方位。 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/service/hadoop-3.2.4/data/journalnode</value>
</property>
<!--装备namenode寄存元数据的目录,默许放到hadoop.tmp.dir下-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/service/hadoop-3.2.4/data/namenode</value>
</property>
<!--装备datanode寄存元数据的目录,默许放到hadoop.tmp.dir下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/service/hadoop-3.2.4/data/datanode</value>
</property>
<!-- 副本数量装备 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--设置用户的操作权限,false表明封闭权限验证,任何用户都能够操作-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!--敞开ResourceManager
HA功用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--标志ResourceManager-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ccyarn</value>
</property>
<!--集群中ResourceManager的ID列表,后边的装备将引证该ID-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 设置YARN集群主人物运转节点rm1-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata01</value>
</property>
<!-- 设置YARN集群主人物运转节点rm2-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata02</value>
</property>
<!--ResourceManager1的Web页面拜访地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>bigdata01:8088</value>
</property>
<!--ResourceManager2的Web页面拜访地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>bigdata02:8088</value>
</property>
<!--ZooKeeper集群列表-->
<property>
<name>hadoop.zk.address</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
<!--启用ResouerceManager重启的功用,默许为false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--用于ResouerceManager状况存储的类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- Nodemanager重启康复机制-->
<!-- ShuffleHandler服务也现已支撑在NM重启后康复曾经的状况-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器施行物理内存约束 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器施行虚拟内存约束 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 敞开日志集合功用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志集合服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保存时刻 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>172800</value>
</property>
<!--Flink相关-->
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
<property>
<name>yarn.app.attempts</name>
<value>3</value>
</property>
<property>
<name>yarn.