mysql查询重复的数据,高效处理重复记录的指南
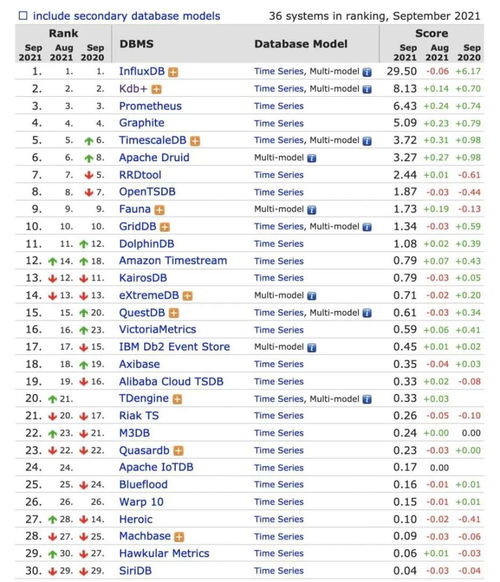
MySQL查询重复的数据通常涉及到找出表中哪些行在某些列上有相同的值。这可以通过使用`GROUP BY`和`HAVING`子句来实现。以下是一个基本的步骤,用于查询重复的数据:
1. 确定需要查询的列:首先,确定哪些列上的数据是重复的。例如,如果你想要找出所有具有相同`name`和`age`的记录,那么这些列就是你需要关注的。
2. 使用`GROUP BY`子句:使用`GROUP BY`子句来按指定的列分组数据。这将允许你按这些列的值来聚合数据。
3. 使用`HAVING`子句:`HAVING`子句通常与`GROUP BY`一起使用,用于过滤分组后的结果。你可以使用`HAVING`子句来找出哪些分组中的记录数大于1,这意味着这些分组包含重复的数据。
4. 选择需要显示的列:在`SELECT`语句中,选择你想要显示的列。通常,你可能会选择那些用来判断重复的列,以及一个计数器来显示每个重复组中有多少条记录。
以下是一个示例SQL查询,它查找了`users`表中所有具有相同`name`和`age`的记录:
```sqlSELECT name, age, COUNT as num_duplicatesFROM usersGROUP BY name, ageHAVING COUNT > 1;```
这个查询将返回所有`name`和`age`组合出现超过一次的记录,以及每个组合出现的次数。
如果你有具体的表结构和查询需求,可以提供更多的信息,我可以帮你编写更精确的查询。
MySQL查询重复数据:高效处理重复记录的指南
在数据库管理中,处理重复数据是一个常见且重要的任务。MySQL作为一款流行的关系型数据库管理系统,提供了多种方法来查询和删除重复数据。本文将详细介绍如何在MySQL中查询重复数据,并提供一些实用的技巧和示例。
一、使用GROUP BY和HAVING子句查询重复数据

在MySQL中,查询重复数据最常用的方法是使用GROUP BY和HAVING子句。这种方法可以帮助我们找出那些在特定列上出现多次的记录。
以下是一个基本的查询重复数据的SQL语句示例:
SELECT columnname, COUNT(columnname)
FROM tablename
GROUP BY columnname
HAVING COUNT(columnname) > 1;
在这个例子中,我们查询了`tablename`表中`columnname`列的重复记录,并且只返回了那些出现次数大于1的记录。
二、使用DISTINCT关键字查询重复数据
DISTINCT关键字可以用来返回不同的值,即不存在重复记录。如果我们查询某个列的不同值,如果返回结果少于总记录数,那么说明存在重复记录。
以下是一个使用DISTINCT关键字查询重复数据的SQL语句示例:
SELECT DISTINCT columnname
FROM tablename
ORDER BY columnname;
在这个例子中,我们查询了`tablename`表中`columnname`列的不同值,并按照列名升序排列。如果结果集中的值少于总记录数,那么说明存在重复记录。
三、使用子查询查询重复数据
子查询可以用来查询符合条件的记录集合,并且可以用在主查询语句中,进行更复杂的查询。以下是一个使用子查询查询重复数据的SQL语句示例:
SELECT columnname
FROM tablename
WHERE columnname IN (
SELECT columnname
FROM tablename
GROUP BY columnname
HAVING COUNT(columnname) > 1
在这个例子中,我们首先在子查询中找到了重复的`columnname`,然后在主查询中选择了这些重复的记录。
四、使用窗口函数查询重复数据(MySQL 8.0及以上版本)
如果你的MySQL版本是8.0及以上,你可以使用窗口函数来查询重复数据。以下是一个使用ROW_NUMBER()窗口函数查询重复数据的SQL语句示例:
SELECT columnname, RANK() OVER (PARTITION BY columnname ORDER BY id)
FROM tablename;
在这个例子中,我们为每个`columnname`的记录分配了一个行号,其中行号是基于`columnname`分区的。行号大于1的记录即为重复记录。
五、删除重复数据
找到重复数据后,你可能需要删除它们。以下是一个删除重复数据的SQL语句示例,假设我们想要保留每个重复记录中ID最小的那条记录:
DELETE t1 FROM tablename t1
INNER JOIN tablename t2
ON t1.columnname = t2.columnname
AND t1.id > t2.id;
在这个例子中,我们通过自连接`tablename`表来找到重复的记录,并删除了ID较大的记录,从而保留了ID最小的记录。
MySQL提供了多种方法来查询和删除重复数据。通过使用GROUP BY、HAVING、DISTINCT、子查询和窗口函数,你可以有效地处理数据库中的重复记录。在实际操作中,请根据具体需求和数据库版本选择合适的方法。
注意:在执行删除操作之前,请确保你已经备份了相关数据,以防止意外删除重要信息。