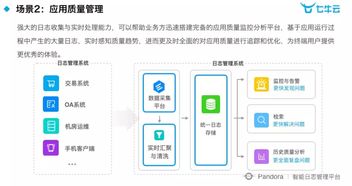
大数据计算框架,大数据计算框架概述
1. Hadoop:Hadoop 是一个开源的、分布式的大数据处理框架,它由 Apache 软件基金会维护。Hadoop 使用 MapReduce 编程模型来处理大数据集,它可以在多台计算机上并行处理数据,从而提高处理速度。
2. Spark:Spark 是一个快速、通用的大数据处理引擎,它提供了丰富的 API,支持多种编程语言,包括 Scala、Java、Python 和 R。Spark 使用内存计算来加速数据处理,它可以在 Hadoop 集群上运行,也可以独立运行。
3. Flink:Flink 是一个开源的、流处理和批处理统一的大数据处理框架。它提供了高吞吐量、低延迟的数据处理能力,支持事件驱动和实时数据处理。
4. Hive:Hive 是一个基于 Hadoop 的数据仓库工具,它提供了 SQL 接口来查询和管理大数据集。Hive 可以将 SQL 查询转换为 MapReduce 作业,以便在 Hadoop 集群上执行。
5. Presto:Presto 是一个开源的、分布式的大数据处理框架,它提供了高速、可扩展的 SQL 查询能力。Presto 可以在多个数据源上执行查询,包括 Hadoop、AWS S3、MySQL 和 PostgreSQL。
6. Drill:Drill 是一个开源的、分布式的大数据处理框架,它提供了低延迟的 SQL 查询能力。Drill 可以在多种数据源上执行查询,包括 Hadoop、NoSQL 数据库和云存储。
7. Dask:Dask 是一个开源的、并行计算框架,它提供了类似于 PyData 堆栈的 API,支持多种编程语言,包括 Python。Dask 可以在单台机器或集群上执行并行计算,它支持多种数据格式,包括 Pandas DataFrame、NumPy 数组和自定义数据类型。
这些大数据计算框架各有其特点和优势,选择适合的框架取决于具体的应用场景和数据需求。
大数据计算框架概述

常见的大数据计算框架

1. Apache Hadoop
Apache Hadoop是一个开源的大数据计算框架,由HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算模型)两大核心组件构成。Hadoop适用于大规模数据集的存储和计算,具有高可靠性、可扩展性和容错性等特点。
2. Apache Spark
Apache Spark是一个快速、通用的大数据计算引擎,支持多种数据处理模式,如批处理、流处理和机器学习等。Spark采用内存计算技术,显著提升了数据处理速度,适用于迭代计算和交互式数据查询等场景。
3. Apache Flink
Apache Flink是一个流式处理和批处理框架,可以实时处理和分析流式数据。Flink支持丰富的窗口操作和状态管理,适用于需要实时处理和分析数据的应用场景。
4. Apache Storm
Apache Storm是一个分布式实时计算系统,适用于处理大规模实时数据流。Storm具有高吞吐量、低延迟和容错性等特点,适用于实时数据处理、实时分析、实时推荐等场景。
5. Mars(火星)框架
Mars是阿里云开发的一个开源分布式计算框架,主要用于解决大数据分析领域中大规模多维数组数据的高效处理问题。Mars具有高性能、灵活性和易用性等特点,适用于机器学习、科学计算等领域。
大数据计算框架的优势与劣势

1. Apache Hadoop
优势:
高可靠性、可扩展性和容错性
适用于大规模数据集的存储和计算
劣势:
MapReduce计算延迟较高,不适合实时计算
编程模型较为复杂,学习曲线较陡峭
2. Apache Spark
优势:
内存计算,数据处理速度快
支持多种数据处理模式,通用性强
劣势:
相对于Hadoop,Spark的生态系统较小
在处理小规模数据时,性能不如Hadoop
3. Apache Flink
优势:
实时处理和分析流式数据
支持丰富的窗口操作和状态管理
劣势:
相对于Spark和Storm,Flink的社区活跃度较低
学习曲线较陡峭
4. Apache Storm
优势:
高吞吐量、低延迟和容错性
适用于实时数据处理、实时分析、实时推荐等场景
劣势:
相对于Spark和Flink,Storm的通用性较差
编程模型较为复杂
5. Mars(火星)框架
优势:
高性能、灵活性和易用性
适用于机器学习、科学计算等领域
劣势:
相对于其他框架,Mars的知名度较低
社区活跃度较低
大数据计算框架在处理海量数据方面发挥着重要作用。选择合适的大数据计算框架,有助于提高数据处理效率,降低计算成本。在实际应用中,应根据具体需求和场景选择合适的大数据计算框架。