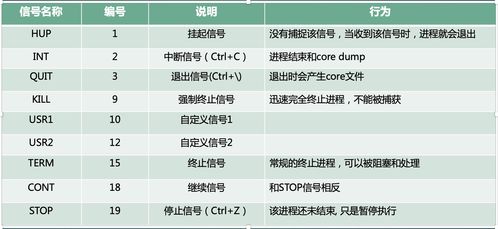
r语言apply函数,数据处理与计算的利器
`apply` 函数是 R 语言中的一个强大工具,它允许用户对矩阵或数据框的列或行应用一个函数。这个函数特别适用于需要对矩阵或数据框的每一列或每一行进行相同的操作,比如计算每一列或每一行的平均值、标准差、最大值、最小值等。
基本语法
`apply`
`X`: 一个矩阵或数据框。 `MARGIN`: 应用于 `X` 的维度。`1` 表示按列应用,`2` 表示按行应用。 `FUN`: 应用于 `X` 的函数。这个函数必须能够接受 `X` 中的列或行作为输入。 `...`: 其他传递给 `FUN` 的参数。
示例
假设我们有一个矩阵 `m`,我们想要计算每一列的平均值。
```rm 这将返回矩阵 `m` 的每一列的平均值。
如果你想要计算每一行的平均值,只需将 `MARGIN` 设置为 `1`。
```rapply```
`apply` 函数还可以用于数据框。例如,假设我们有一个数据框 `df`,我们想要计算每一列的平均值。
```rdf 这将返回数据框 `df` 的每一列的平均值。
注意事项
`apply` 函数通常返回一个向量,但是也可以返回一个矩阵或数据框,这取决于 `FUN` 函数的返回值。 `apply` 函数的效率通常比循环高,因为它在内部进行了优化。 当使用 `apply` 函数时,需要确保 `FUN` 函数能够接受 `X` 中的列或行作为输入。
深入解析R语言中的apply函数:数据处理与计算的利器
在R语言中,apply函数是一个强大的数据处理工具,它能够简化对矩阵或数据框的行或列进行操作的过程。本文将深入解析apply函数的用法、原理以及在实际应用中的优势。
一、apply函数简介
apply函数是R语言中用于对矩阵或数据框的行或列进行操作的函数。它可以将一个函数应用于矩阵或数据框的指定维度,并返回结果。apply函数的语法如下:
apply(X, MARGIN, FUN, ...)
其中:
X:要应用函数的数据集,可以是矩阵、数据框或数组。
MARGIN:指定函数应用的维度,1代表行,2代表列,c(1,2)代表同时应用于行和列。
FUN:要应用的函数。
...:其他可选参数。
二、apply函数的用法示例
示例1:计算矩阵的每一行和每一列的和
示例2:找出矩阵中每一列的最大值所在位置
apply(y, 2, which.max) 找出每一列的最大值所在位置
示例3:对矩阵进行自定义函数操作
apply(y, 1, function(x) {x^2}) 对每一行进行平方操作
apply(y, 2, function(x) {x^2}) 对每一列进行平方操作
三、apply函数的优势
相比于传统的循环结构,apply函数具有以下优势:
代码简洁:apply函数能够将复杂的循环结构简化为一行代码,提高代码的可读性和可维护性。
执行效率:apply函数在内部进行了优化,能够提高数据处理和计算的效率。
易于扩展:apply函数可以方便地应用于不同类型的数据结构和函数,具有较好的扩展性。
四、apply函数的注意事项
在使用apply函数时,需要注意以下几点:
确保函数FUN能够正确处理矩阵或数据框的行或列。
当处理大型数据集时,apply函数可能会消耗较多内存和计算资源。
在使用apply函数时,建议先对数据进行预处理,以提高计算效率。
apply函数是R语言中一个强大的数据处理工具,能够简化对矩阵或数据框的行或列进行操作的过程。通过本文的介绍,相信您已经对apply函数有了更深入的了解。在实际应用中,熟练掌握apply函数将有助于您提高数据处理和计算的效率。