机器学习 数据预处理,迈向高效模型构建的关键步骤
1. 数据清洗:删除或修正缺失、错误或重复的数据。2. 数据集成:合并来自多个来源的数据。3. 数据转换:包括归一化、标准化、编码等,以使数据适合模型。4. 特征选择:选择与目标变量最相关的特征。5. 特征工程:创建新的特征以增强模型性能。
数据预处理是机器学习项目中不可或缺的一部分,它直接影响模型的准确性和效率。
机器学习数据预处理:迈向高效模型构建的关键步骤

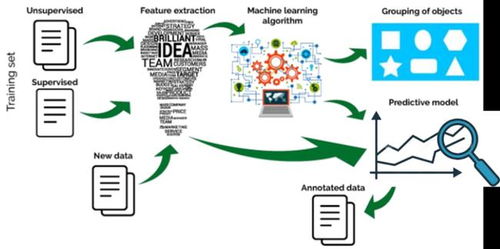
在机器学习领域,数据预处理是确保模型性能和准确性的关键步骤。数据预处理不仅包括数据的清洗、转换和标准化,还包括特征提取和选择。本文将深入探讨机器学习数据预处理的重要性、常用方法和最佳实践。
一、数据预处理的重要性
数据预处理是机器学习流程中的第一步,其重要性不容忽视。以下是数据预处理对模型构建的几个关键影响:
提高模型性能:通过数据预处理,可以去除噪声、异常值和缺失值,从而提高模型的准确性和泛化能力。
减少过拟合:数据预处理有助于减少模型对训练数据的依赖,降低过拟合的风险。
提高计算效率:通过数据预处理,可以减少模型训练所需的时间和资源。
二、数据预处理常用方法
数据预处理主要包括以下几种方法:
1. 数据清洗
数据清洗是数据预处理的基础,主要包括以下步骤:
去除重复数据:重复数据会误导模型,影响模型的性能。
处理缺失值:缺失值会影响模型的训练和预测,需要采取适当的策略进行处理,如删除、填充或插值。
处理异常值:异常值可能对模型产生负面影响,需要识别并处理。
2. 数据转换
数据转换包括以下几种方法:
标准化:将数据缩放到一个固定范围,如[0, 1]或[-1, 1],以便模型更好地处理。
归一化:将数据转换为具有相同均值的分布,如均值为0,标准差为1的正态分布。
3. 特征工程
特征工程是数据预处理的重要环节,主要包括以下步骤:
特征提取:从原始数据中提取新的特征,如计算平均值、方差、最大值、最小值等。
特征选择:从提取的特征中选择最有用的特征,以减少模型复杂度和提高性能。
特征组合:将多个特征组合成新的特征,以增强模型的预测能力。
三、数据预处理最佳实践
以下是数据预处理的一些最佳实践:
了解数据:在开始数据预处理之前,了解数据的来源、结构和分布非常重要。
逐步处理:将数据预处理分为多个步骤,逐步进行,以便更好地控制整个过程。
可视化数据:使用可视化工具分析数据,以便更好地理解数据的分布和特征。
记录预处理过程:记录数据预处理的过程和结果,以便后续分析和复现。
数据预处理是机器学习流程中的关键步骤,对于提高模型性能和准确率具有重要意义。通过了解数据预处理的重要性、常用方法和最佳实践,我们可以更好地处理数据,为模型构建奠定坚实的基础。